Implicit Neural Representations (INRs) have shown great promise in solving inverse problems, but their lack of inherent regularization often leads to a trade-off between expressiveness and smoothness. While Lipschitz continuity presents a principled form of implicit regularization, it is often applied as a rigid, uniform 1-Lipschitz constraint, limiting its potential in inverse problems.
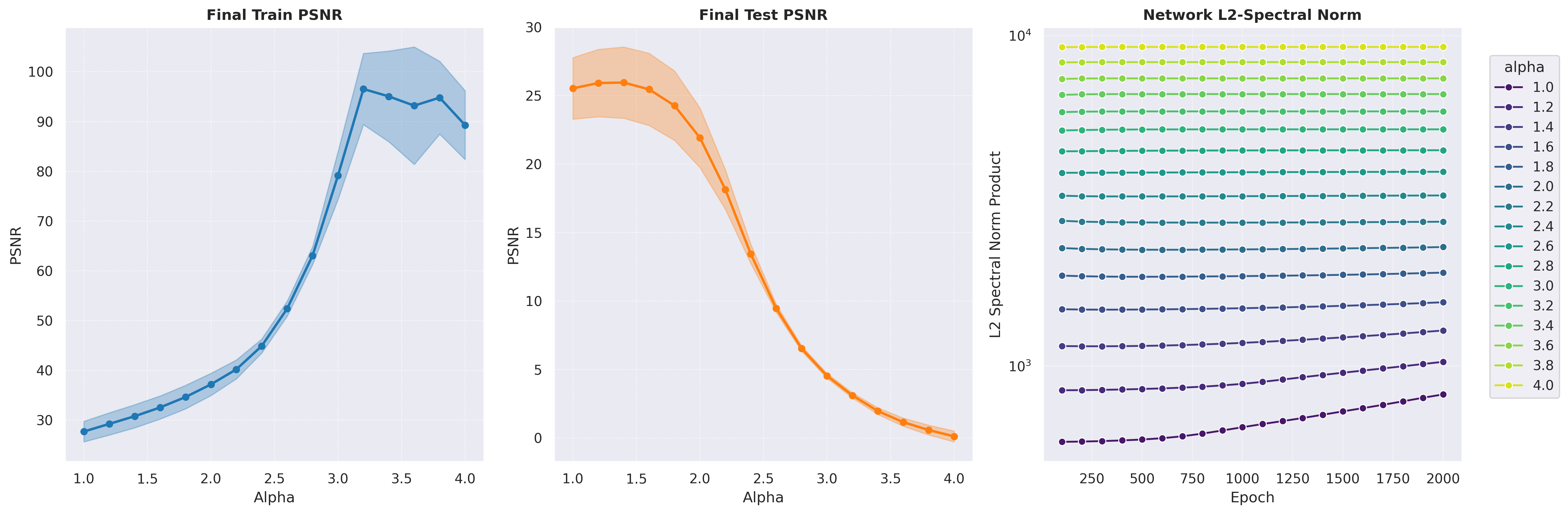
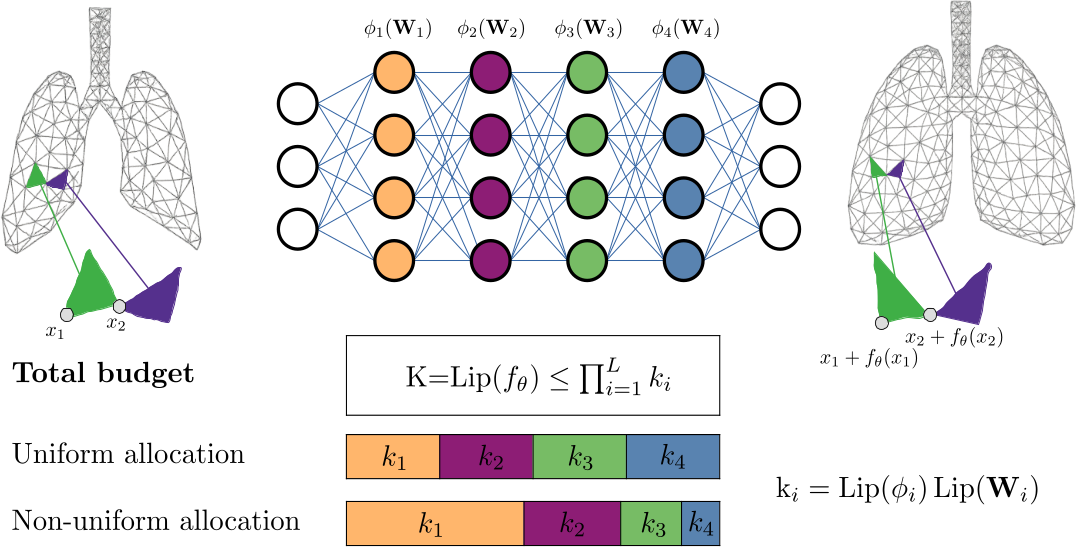
In this work, we reframe Lipschitz regularization as a flexible Lipschitz budget framework. We propose a method to first derive a principled, task-specific total budget K, then proceed to distribute this budget non-uniformly across all network components, including linear weights, activations, and embeddings.
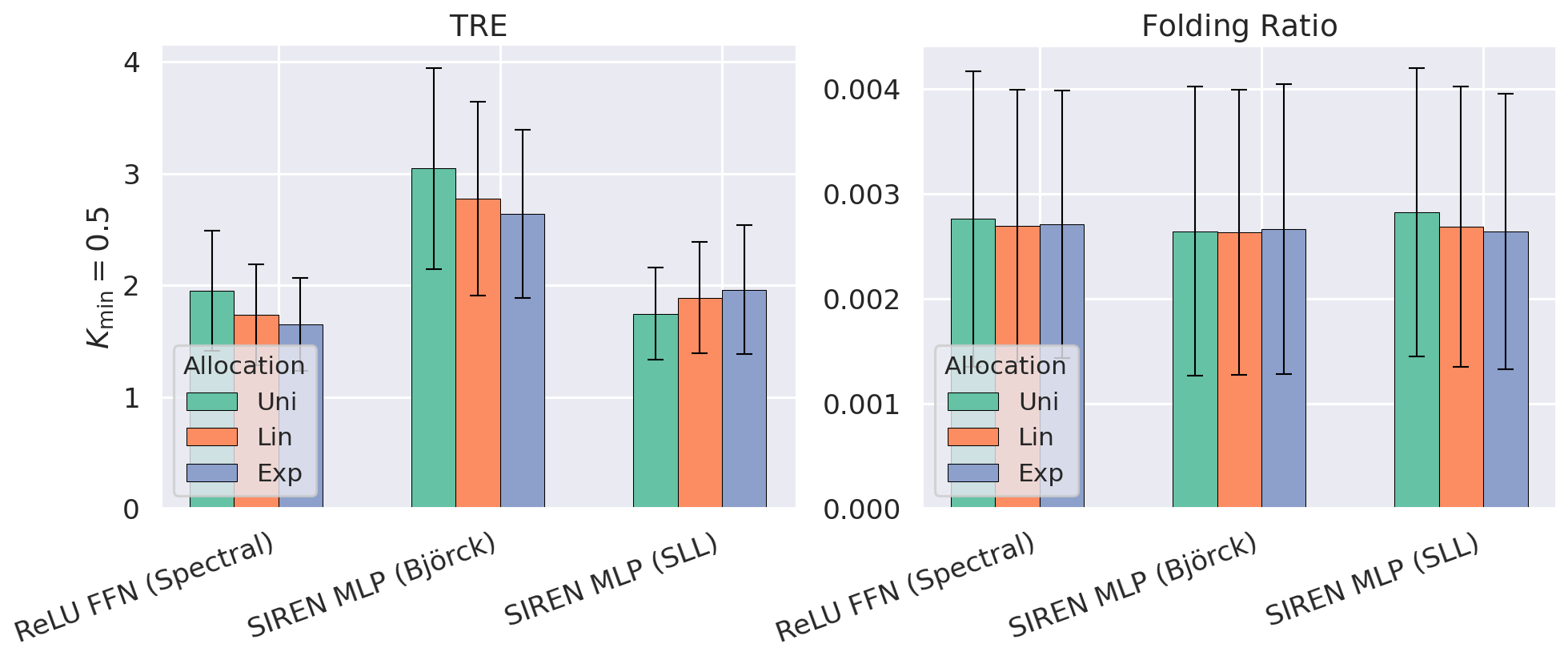
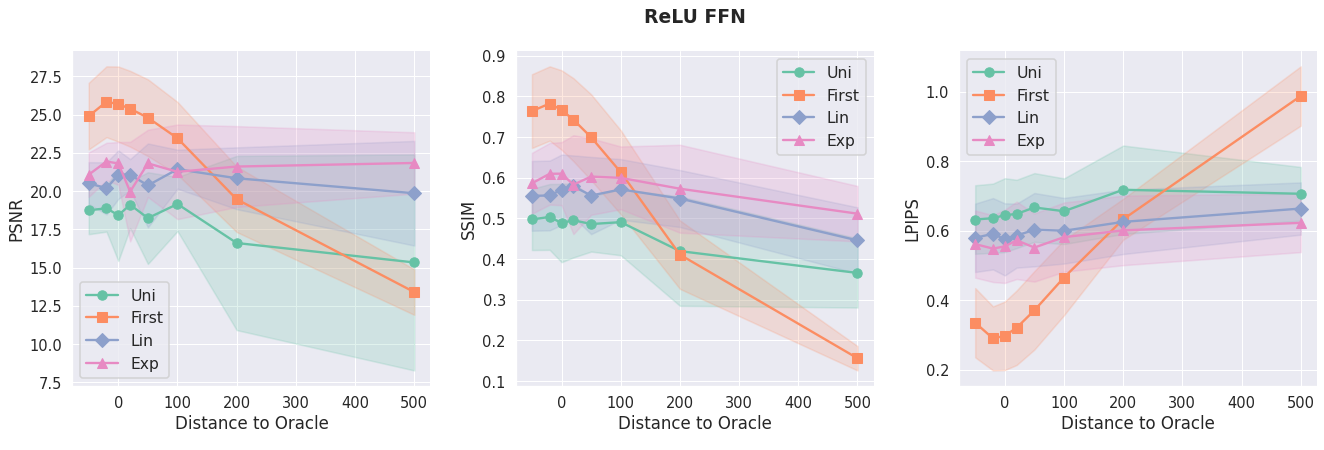
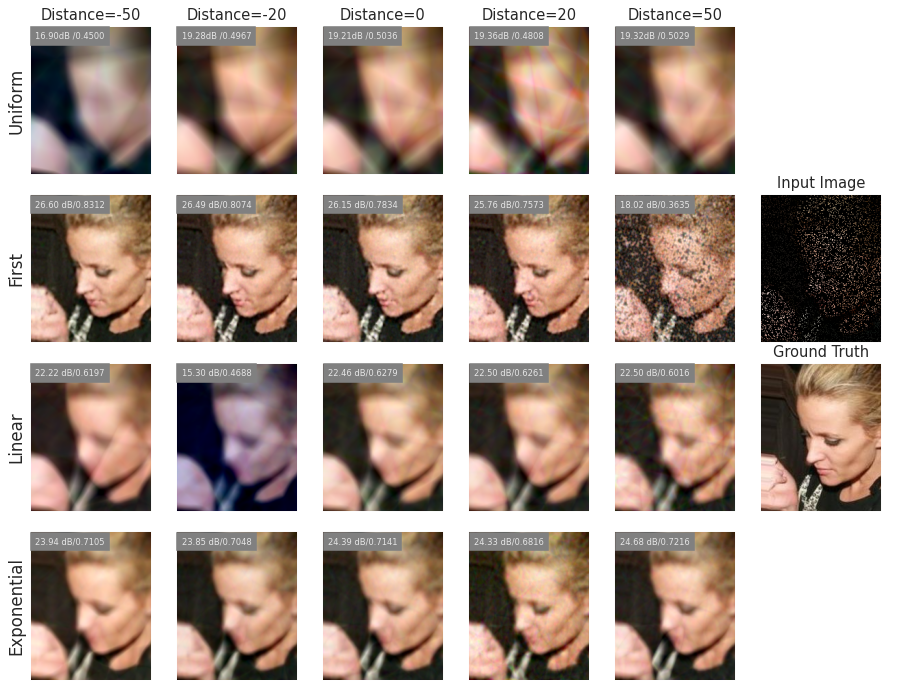
Across extensive experiments on deformable registration and image inpainting, we show that non-uniform allocation strategies provide a measure to balance regularization and expressiveness within the specified global budget. Our Lipschitz lens introduces an alternative, interpretable perspective to Neural Tangent Kernel (NTK) and Fourier analysis frameworks in INRs, offering practitioners actionable principles for improving network architecture and performance.